sub13_session4_mov1
Human Pose Estimation (HPE) aims to predict the keypoints of each person from perceived signals. RGB frames based HPE has experienced a rapid development benefiting from deep learning. While it still meets challenges with the drawbacks of frame-based cameras. The prediction of keypoints in scenarios with motion blur or high dynamic range will be inaccurate.
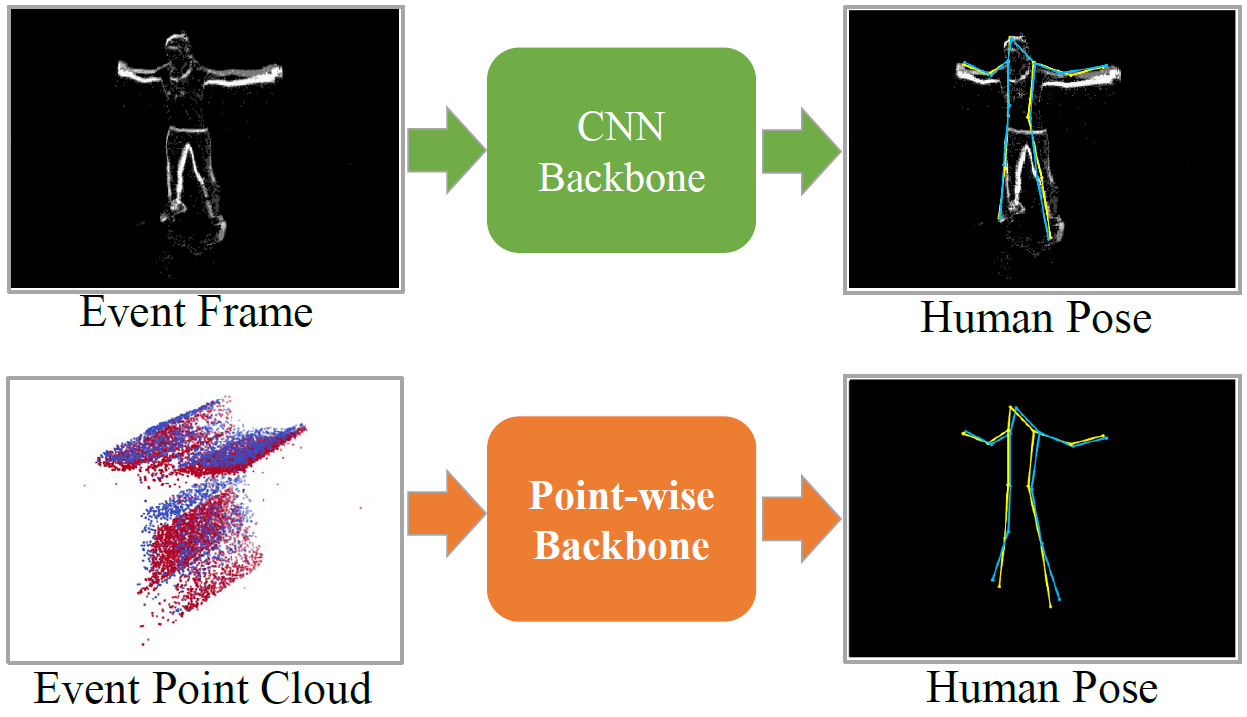
Event cameras, such as the Dynamic Vision Sensor (DVS), is a kind of bio-inspired asynchronous sensor responding to changes in brightness on each pixel independently, with higher dynamic range (over 100dB) and larger temporal resolution (in the order of μs). Event cameras can tackle the disadvantages of frame-based cameras, which could maintain stable output in such extreme scenes. Event-based HPE has not been fully studied, remaining great potential for applications in extreme scenes and efficiency-critical conditions. In this project, we are the first to estimate 2D human pose directly from 3D event point cloud.
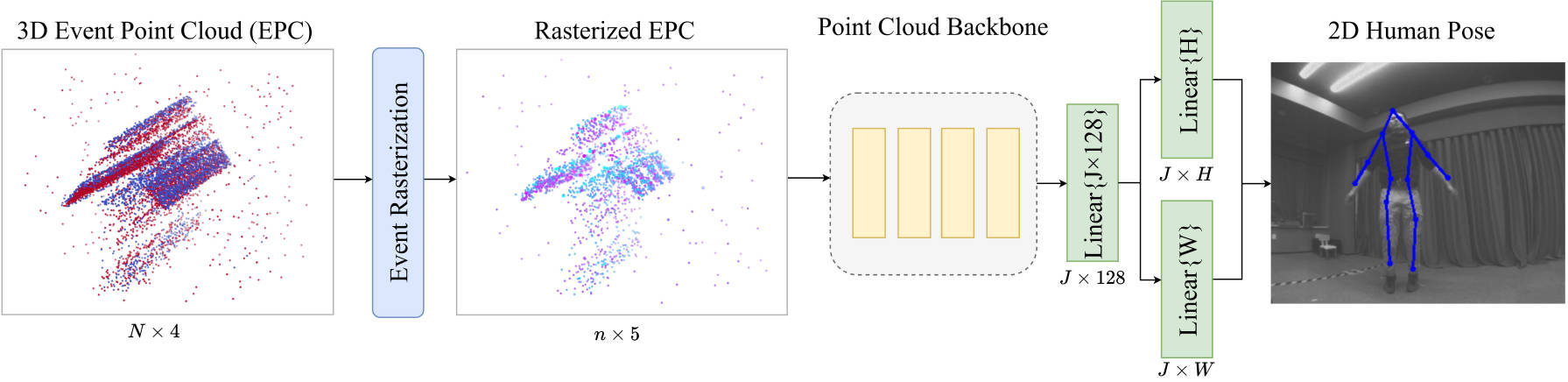
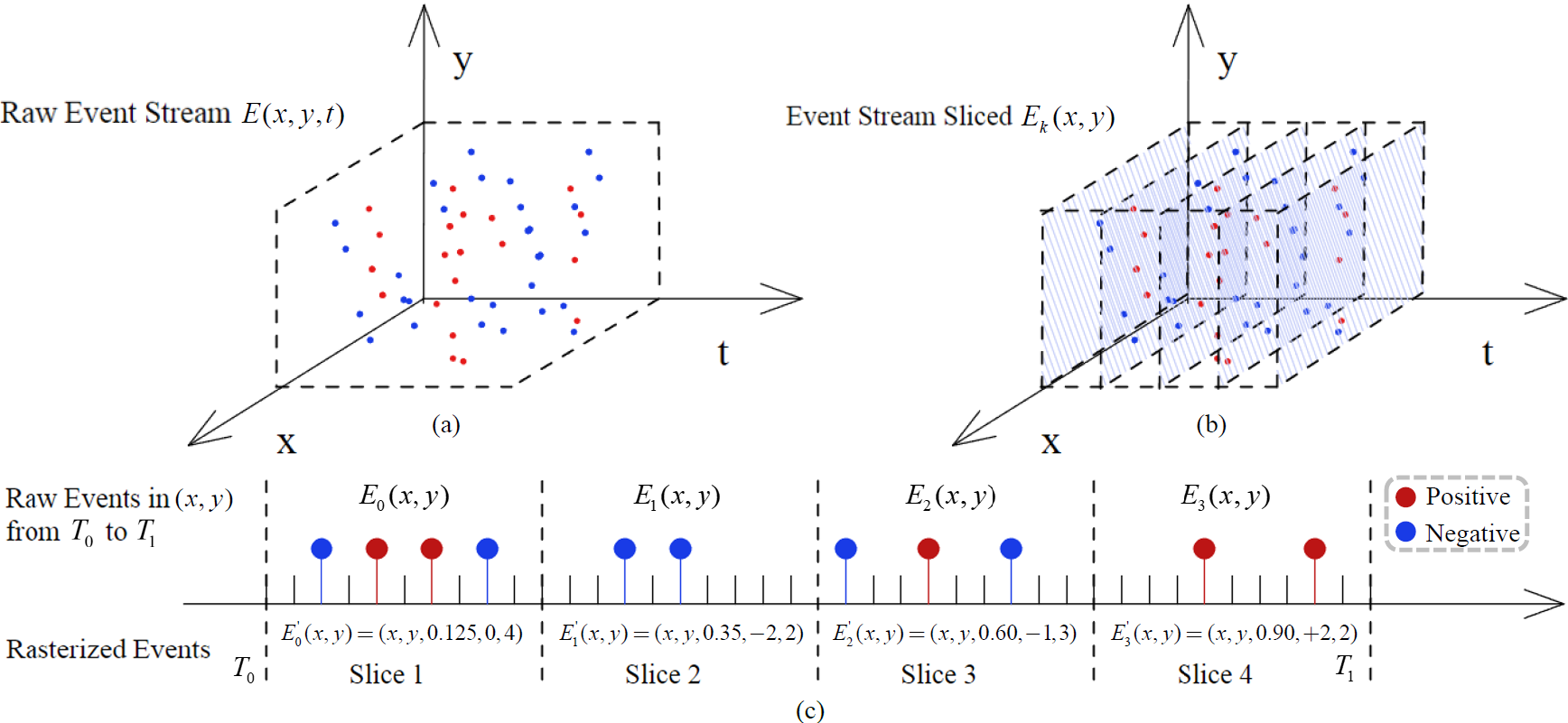
We explore the feasibility of estimating human pose from 3D event point clouds directly, which is the first work from this perspective to our best knowledge. We demonstrate the effectiveness of well-known LiDAR point cloud learning backbones for event point cloud based human pose estimation. We propose a new event representation, rasterized event point cloud, which maintains the 3D features from multiple statistical cues and significantly reduces memory consumption and computational overhead with the same precision.
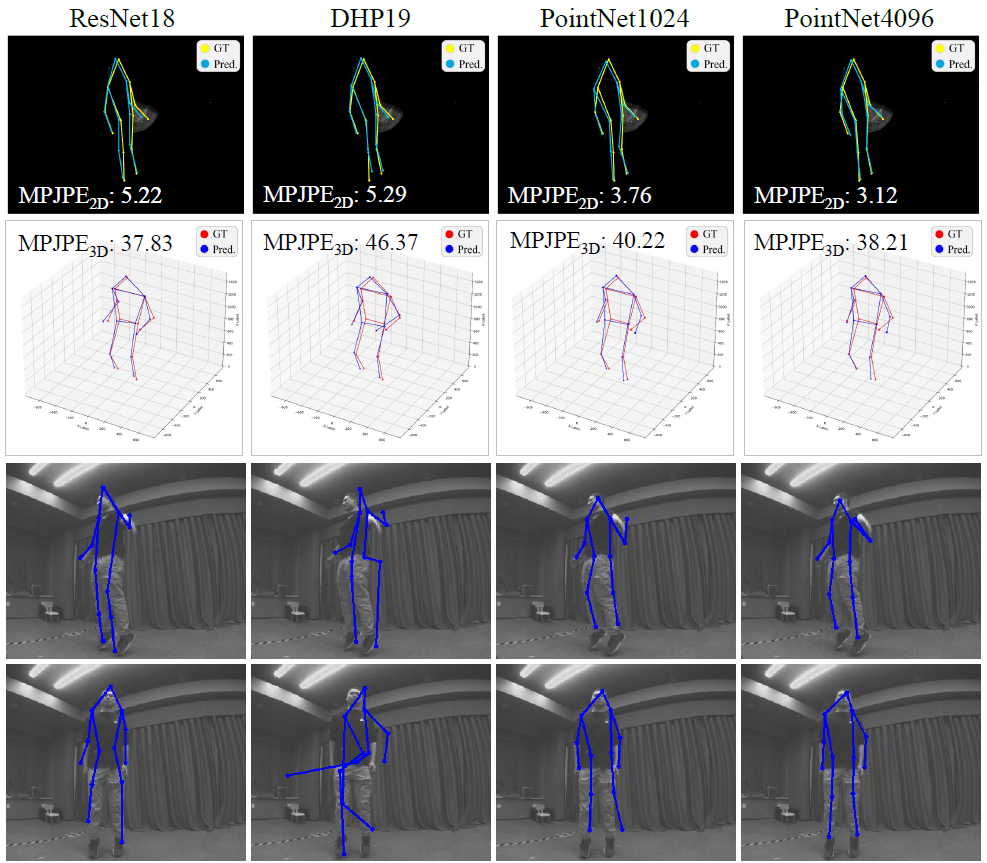
Our method based on PointNet with 2048 points input achieves 82.46mm in MPJPE3D on the DHP19 dataset, while only has a latency of 12.29ms on an NVIDIA Jetson Xavier NX edge computing platform, which is ideally suitable for real-time detection with event cameras.
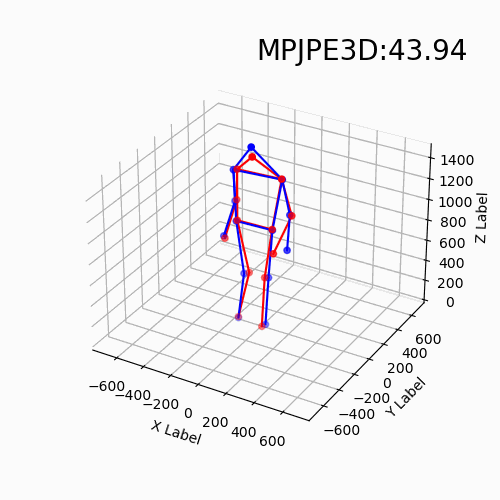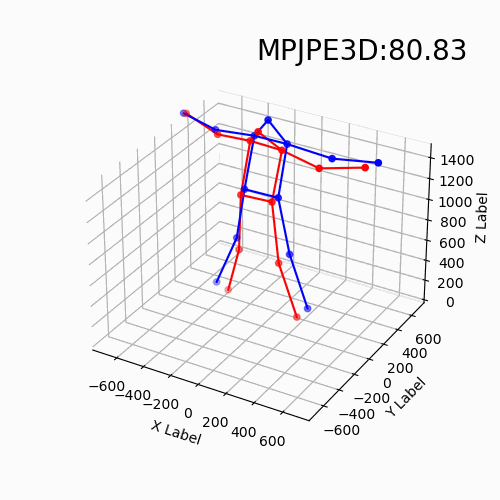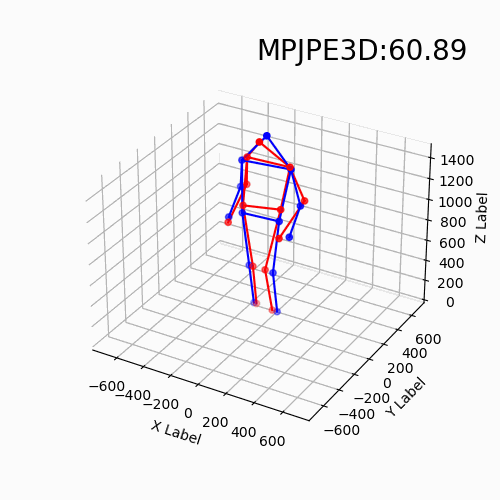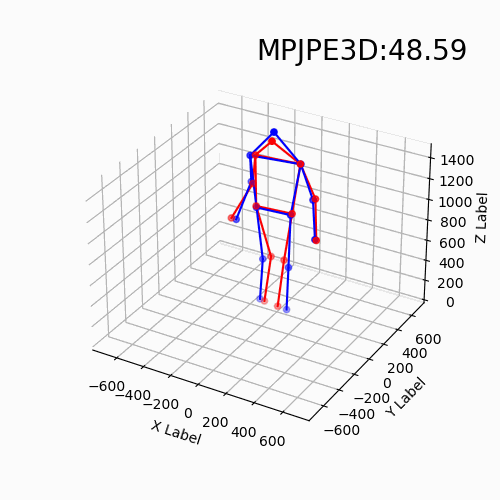
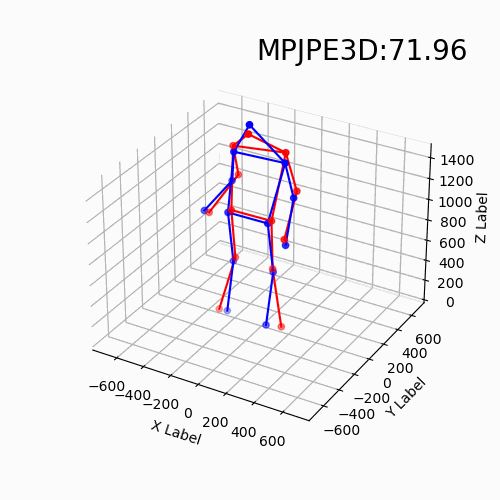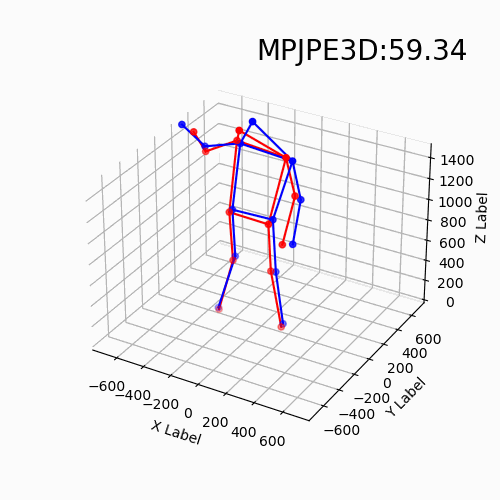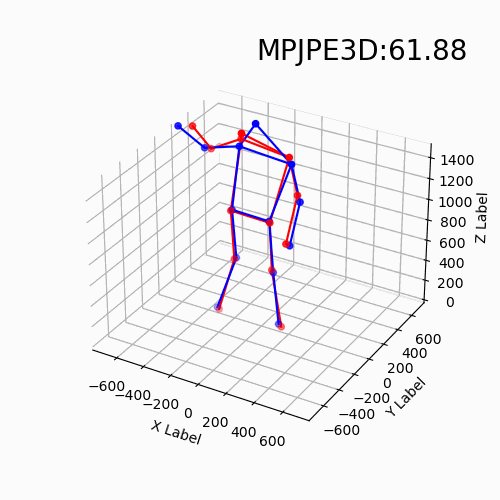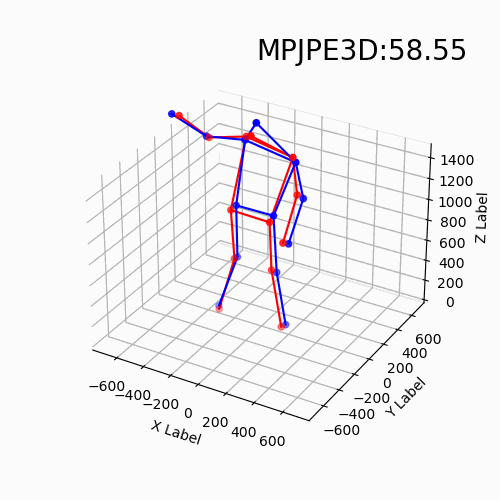
For the new data with different devices, our approach still delivers impressive results. Moreover, we find that the DHP19 model fails on the new data despite the conducted denoising and filtering. While, our models based on event point cloud with a multidimensional feature generalize well to such unseen domains and is robust to the noise brought by the background as well as the device itself.

We find that our event point cloud based method is more robust when facing static limbs than the DHP19 model. Static limbs during the movement generate few events which lead to invisible parts when accumulating events to a constant count event frame. However, such few events are retained in the event point cloud, and they could be processed by the point-wise backbone more effectively.
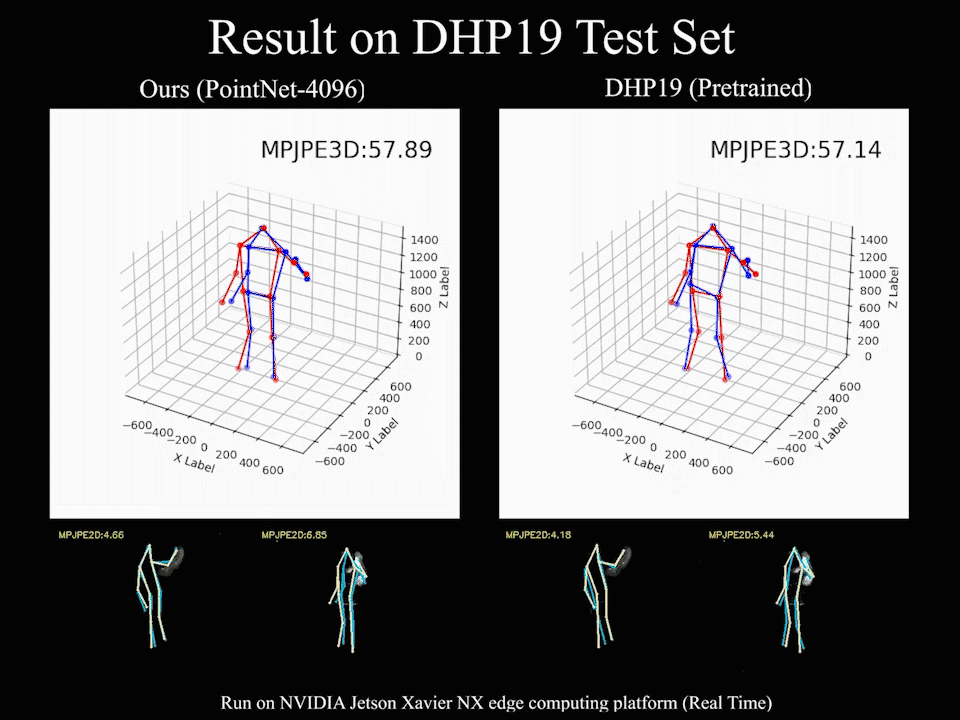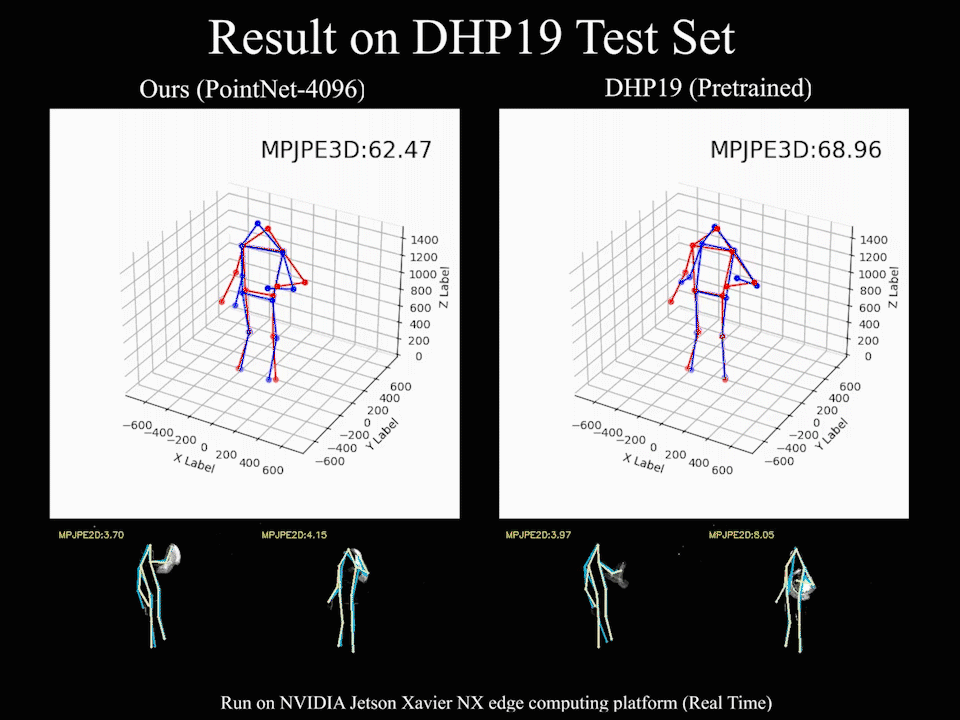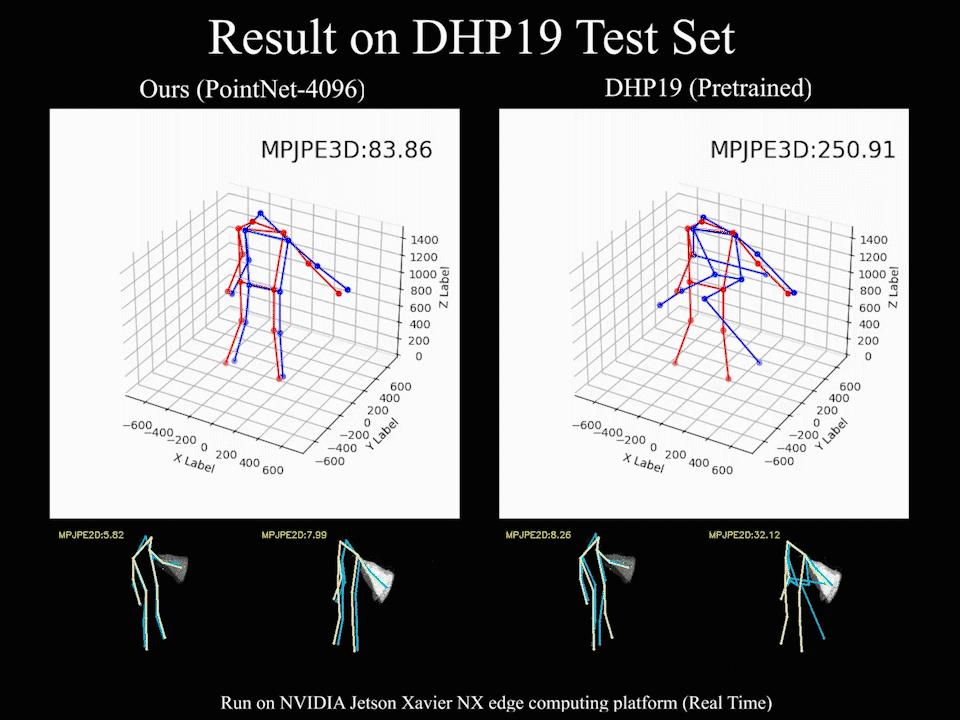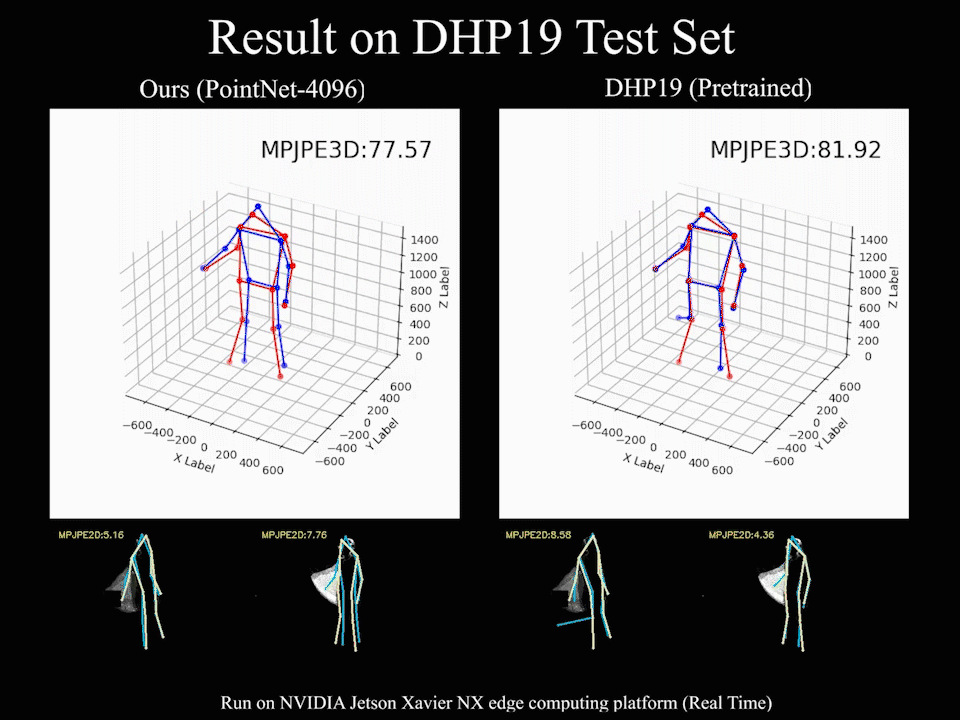
@inproceedings{chen2022EPP,
title={Efficient Human Pose Estimation via 3D Event Point Cloud},
author={Chen, Jiaan and Shi, Hao and Ye, Yaozu and Yang, Kailun and Sun, Lei and Wang, Kaiwei},
booktitle={2022 International Conference on 3D Vision (3DV)},
year={2022}
}